Machine Maintenance Using Smarten Assisted Predictive Modelling!
Machine Maintenance Using Smarten Assisted Predictive Modelling!
Home > Explore/Learn > Blog > Machine Maintenance Using Smarten Assisted Predictive Modelling!
1. Machine Maintenance is always cheaper then downtime!
Sooner or later, all machines run to fail and monitoring the condition of the machine is crucial for any enterprise as any unplanned downtime can have greater economic impact resulting in reduced productivity and ultimately losing the customers. That being so, a regular way to keep the machine in a good condition is to timely monitor it and detect the patterns to predict the breakdowns. Predictive maintenance of machines helps in evaluating the timely collected machine data in order to gage its condition and predict when maintenance work is needed.
2. Better the data, Profound is the insight!
Now that we have a broader understanding of the machine maintenance use case, the next apparent step is to comprehend the data needed for exploratory analysis. Our dataset will be parametric and there will be many parameters upon which our target to know whether the machine will fail will rely upon. By and large, considering IOT sensor data, wherein the machine contains many sensors which helps it to function properly, our dataset must contain the timely measurements from each sensor in order for us to track the patterns for machine failure. Also, the majority of machines have dependency upon its surrounding environment, so in many cases, recording timely temperature and humidity conditions and other affecting parameters can also play an essential role in determining machine breakdown. It goes without saying that our dataset must also have a date and time field intended to remark the failure patterns, previous date and time when the machine failed to perform and also sometimes to speculate the remaining life of the machine.
3. Smarten Assisted Predictive Modelling: Take the guesswork out of planning!
Every organization must plan and forecast results. If the enterprise is to succeed, it must strive for accuracy and identify trends and patterns in the market and industry that will help it to predict future results, plan for growth and capitalize on opportunities. Smarten Insight provides predictive modelling capability and auto-recommendations and auto-suggestions to simplify use and allow business users to leverage predictive algorithms without the expertise and skill of a data scientist. Let’s get a taste of how Smarten Assisted Predictive Modelling can equip business users in providing insights upon machine maintenance tasks.
4. If we have data, let’s look at it!
Any kind of analysis initiates by looking upon the data. Keeping a note that we already have a predefined dataset uploaded to Smarten, let’s get started slowly but surely into how to open a loaded dataset in Smarten and make analysis.
Open a loaded dataset in Smarten:
Go to Open -> Data in top right dropdown in Smarten
Search for the dataset to analyse
Examine the dataset
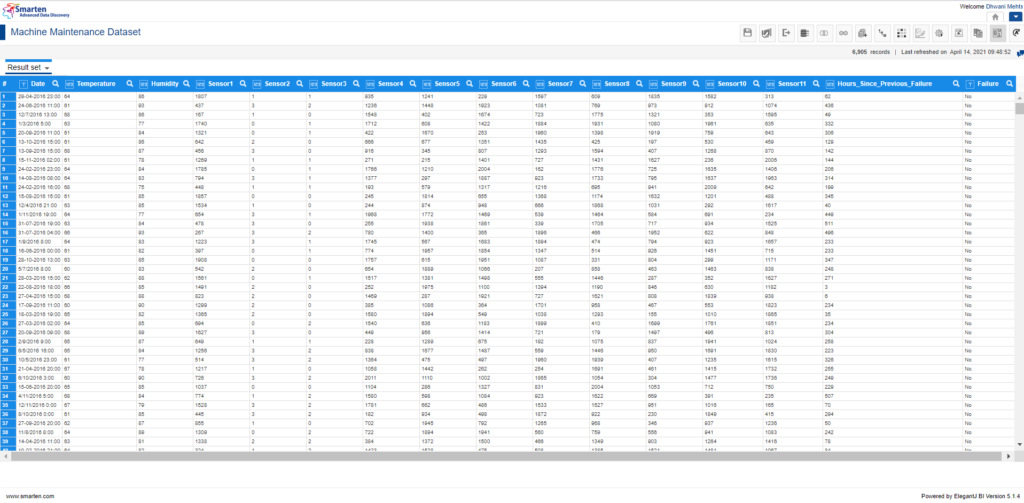
On opening the dataset, you will be able to view the attributes (columns) for the machine maintenance use case and also be able to draw some superficial insights by pondering upon the dataset. Your dataset will look as follows:
Machine Maintenance Dataset View
Perform Elementary Data Analysis from Dataset:
From the dataset, we can perceive that there are multiple factors (i.e., attributes or columns) which may have an effect on our target variable (i.e., failure). Machine failure is evidently splitted into two categories (i.e., yes and no) based upon whether it has undergone breakdown at the date and time when the corresponding observations were made. Also, on catching a sight on the dataset, we can figure out that here we are dealing with a very generic dataset where we have many sensors impacting our machine failure. These sensors can be temperature sensors, humidity sensors, pressure sensors, proximity sensors, level sensors, accelerometers, infrared sensors, optical sensors, gyroscope sensors and so on depending upon the machine of interest. Here we are not limiting our study for any specific machine but aim at exploring the use case in general with Smarten Assisted Predictive Modelling.
Now it’s time to gear up with some amazing data analytics using Smarten!
5. The goal is to turn Data into Information and Information into Insight!
Smarten provides us with a feature of Smarten Assisted Predictive Modelling which reduces the time and skills required to produce accurate, clear results, quickly using machine learning. With Smarten Insights, the user will simply have to select the dataset to be analysed and the broad category of the algorithm to be applied. That’s it! The system will interpret the dataset, select important columns of data, analyse its type and variety and other parameters and then use intelligent machine learning to automatically apply the best algorithm in the selected algorithm technique in order to provide data insights.
Let’s gradually familiarize ourselves with Smarten Insights!
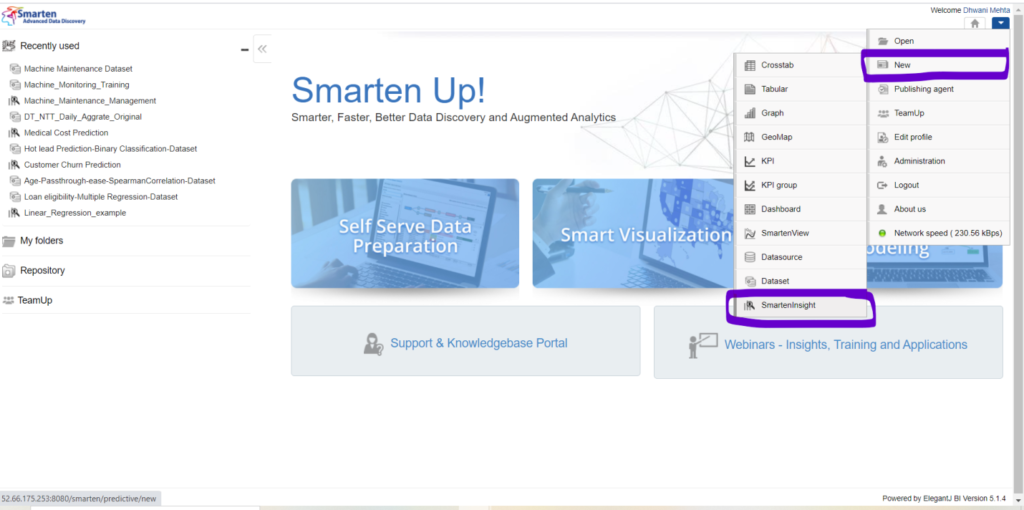
5.1 Create a fresh New Smarten Insight:
Go to New -> SmartenInsight Menu in the dropdown provided in the top right corner of the Smarten Dashboard.
Creating a new Smarten Insight
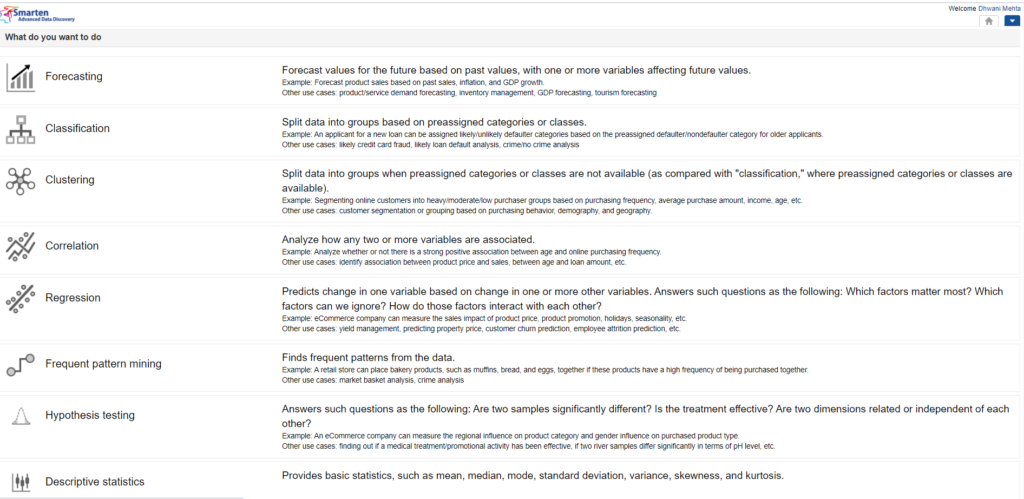
5.2 What do you want to do? Choose Algorithm Technique Accordingly:
The following window opens on selecting Smarten Insight:
Choosing suitable Algorithmic Technique from Smarten Insight
Smarten has a provision wherein users can select the algorithm technique best sufficing their use case and provide quality results for the chosen technique. In order to select the best category of algorithm, users need to have some basic data literacy.
We need to choose the best algorithm technique from the following list:
Forecasting
Classification
Clustering
Correlation
Regression
Hypothesis Testing
Frequent Pattern Mining
Descriptive Statistics
Let’s put our thinking caps on and try to recognize the best suit algorithm technique for our Machine Maintenance dataset!
The high-level goal is pretty clear that we are keen to predict whether the given machine will breakdown provided other parameters. So, we are basically interested in splitting (or categorizing) our outcome based upon whether the machine will fail(yes) or not (no). This suggests that our problem can be prototyped as a classification task because our outcome domain is finite (i.e., outcome has only two values, failure and non-failure).
Acknowledging this study, we can carry forward with our process of getting insights using Smarten by selecting the Classification model from the list of other algorithmic techniques. Smarten also has a provision to provide description against each algorithm technique along with a basic example to enhance data literacy and assist us in algorithm selection.
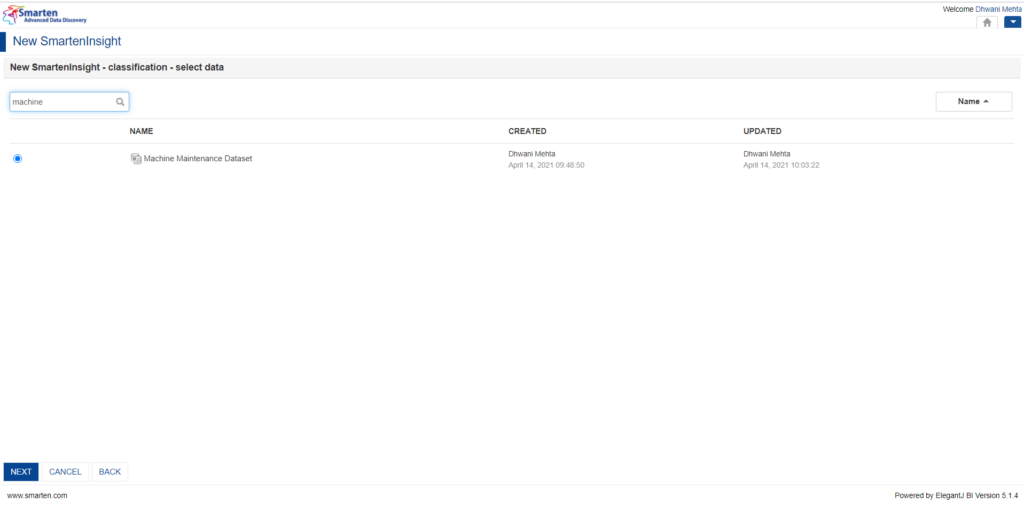
5.3 Select the data for Performing Classification upon:
Search for the dataset (In our case it’s named Machine Maintenance Dataset) from the search bar.
Select the radio button against the dataset of interest.
Click on the next button at the bottom to advance the procedure.
Perform Search Operation for Dataset of Interest
5.4 Smarten identifies target (outcome variable) and predictors (dependent variables) for us:
Smarten cleverly identifies the targets and predictors from chosen dataset
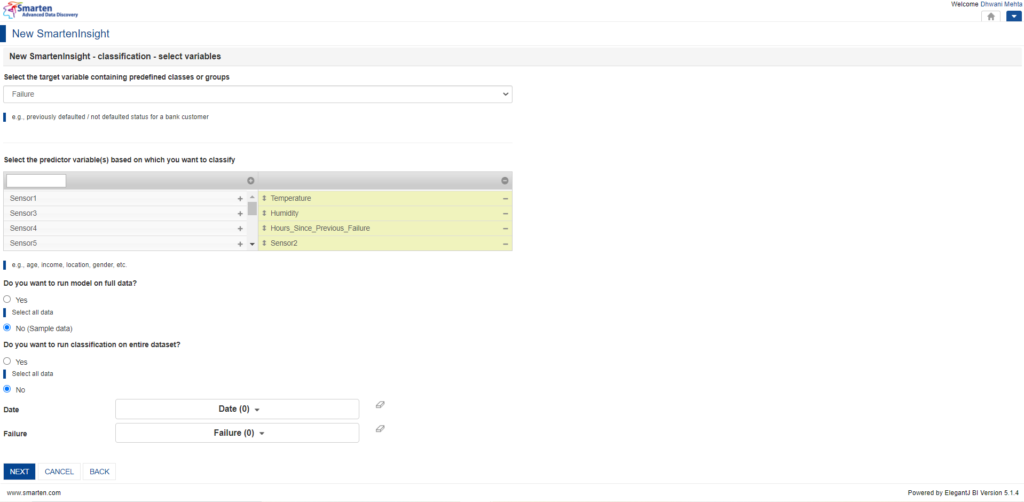
5.5 Select the target and predictors based upon your choice:
After Smarten identifies the target and predictor attributes, users still have the flexibility to make alterations.
Auto Suggested attributes by Smarten Insight
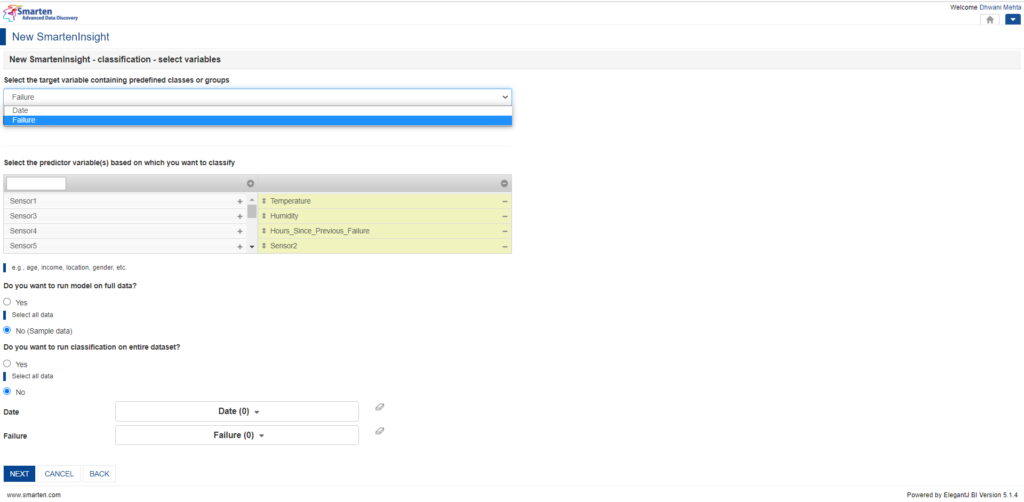
5.5.1 Target selection:
We would want failure to be our target variable to fulfil our motive of figuring out whether or not the machine will fail provided the other parameters. Hence, we can select that from the dropdown indicating ‘Select the target variable containing predefined classes or groups. For this scenario, smarten has cleverly identified failure to be a target feature for us and we retain this selection.
Making Target selection for classification
5.5.2 Identify recommended predictors for selected Target:
Smarten has a feature wherein it selects the significant predictors for the chosen target using machine learning techniques. The predictors highlighted in yellow are those which showcase significant impact upon our target variable (i.e., Failure).
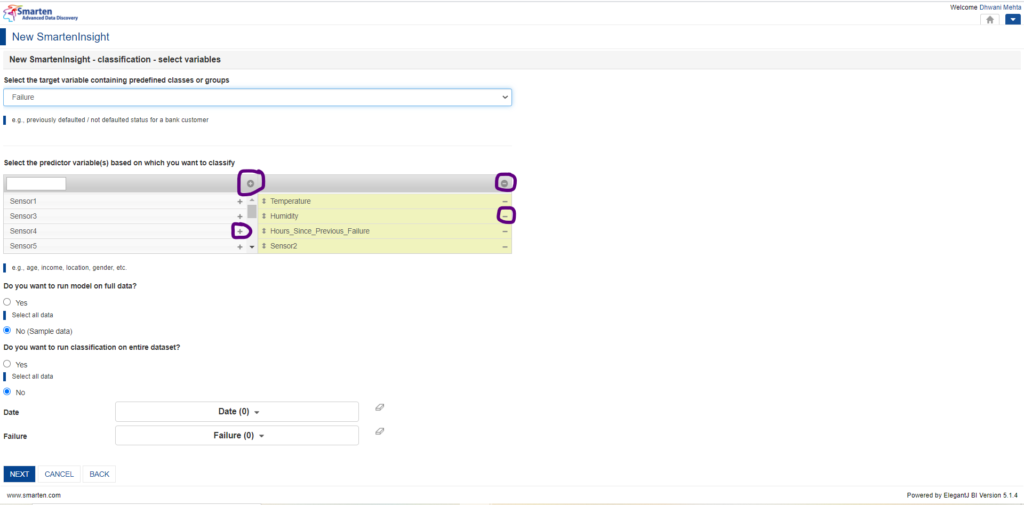
Significant Predictors auto selected by Smarten
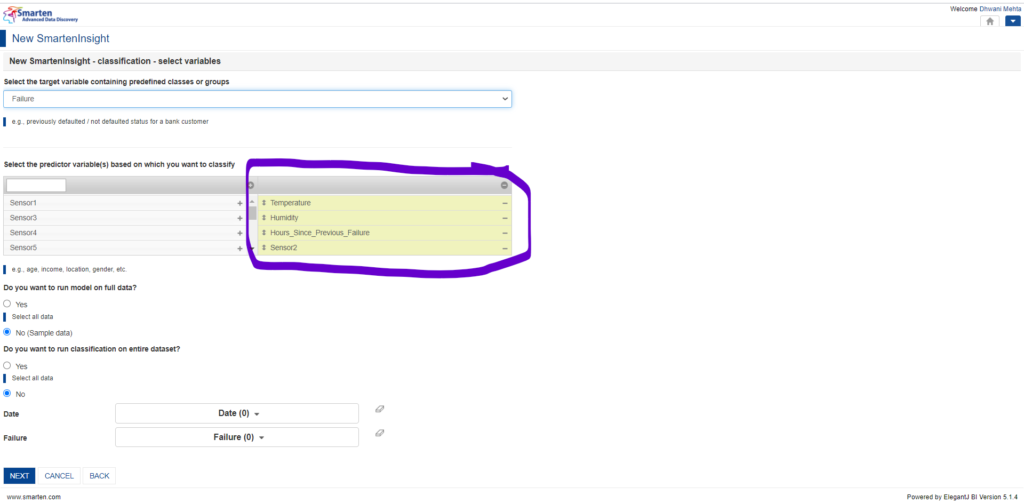
5.5.3 Perform changes in Predictors (Optional):
Now that Smarten has equipped us well with the significant predictors, we still have a choice to add or remove the predictor selections based upon our interest.
Smarten provides users flexibility for predictor selection
The left side table corresponds to the available predictor list and the right side indicates the selected attributes which shall be provided for processing the machine learning model. The + icon beside each attribute in the available attribute column leads them to the selected attribute columns which are to be processed by our classification model. Similarly, users have flexibility in removing them from the selected attribute column by the – icon. In case of selecting all the available attributes for processing, ⊕icon at the top serves the purpose. ⊖icon serves the purpose of deselecting all the selected attributes. Apart from this, Smarten also has a provision wherein the users can directly search for any available attribute by name from the search bar. This essentially helps when there is a huge number of available attributes and users want only a handful of them to be quickly pre-processed!
From the default selection, we get to acknowledge that Sensor2 has significant impact upon machine failure, but suppose we want to designate the machine breakdown based upon Sensor4 (say proximity sensor), then we can make predictor selection accordingly. Currently taking into account the default selection, let’s jump further for our analysis.
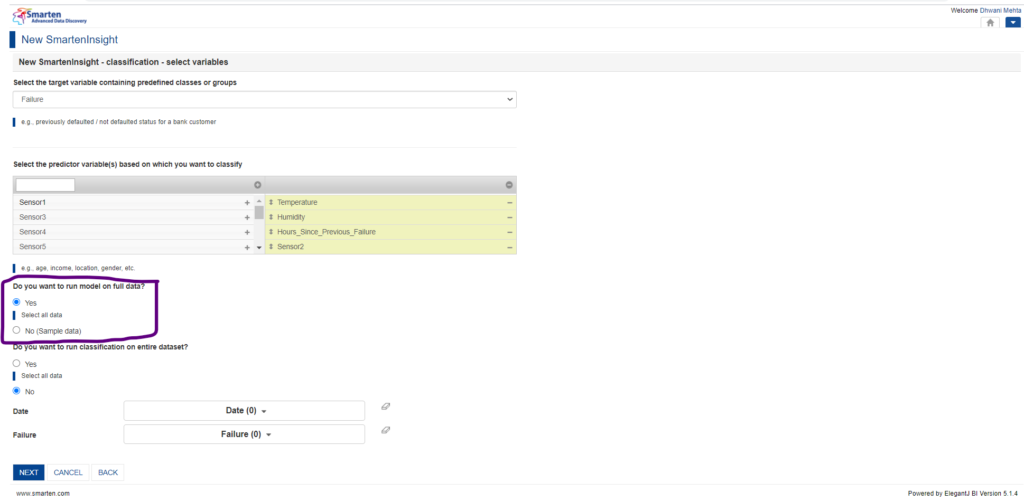
5.6 Run model on full or sample data option:
Sometimes, perhaps in most cases, we have to deal with huge data. Our machine learning model may take a longer period to run and provide us with the required outcome. In such a scenario Smarten provides us with an option of using sampled data wherein it smartly makes a sample of data resembling the full data which may give us the same result set as we would have obtained in the full data.
But for the current scenario, we can use the full data to feed to the model by selecting the full data mode radio button.
Full data mode and Sample data mode option in Smarten Insight
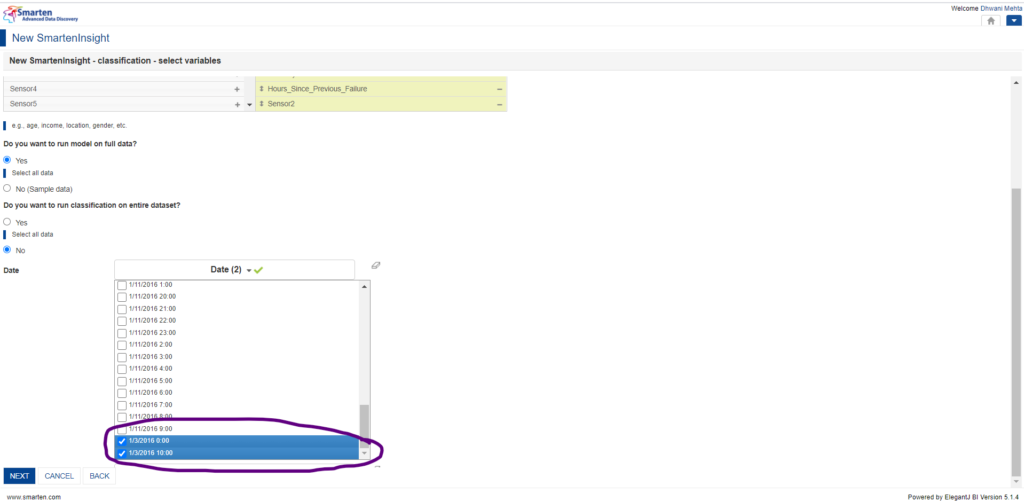
5.7 Want to run classification on entire dataset option:
Often users are keen at making analysis upon some filtered data. Say for instance, what if we were to examine machine breakdowns only in the month of March, then we can make such a filter upon our data, keeping all the other predictors as they are. For such a filtration, Smarten provides us with an option to run classification on the entire dataset or filtered dataset.
Filtering Data to be processed for Classification Technique
If we have no such filtering condition in mind, we can carry further with yes option. After performing the above effortless process, finally click on the next button which will let Smarten designate the best fit classification algorithm using machine learning tactics for our dataset.
Smarten recommends the best fit classification algorithm
6. So that was the recipe, Now let’s taste it!
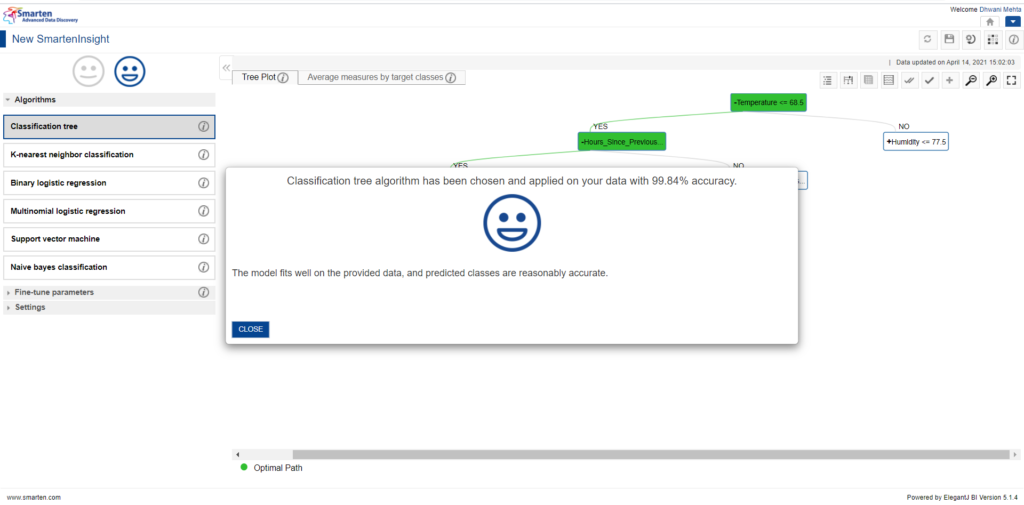
On clicking the next button, Smarten leads us to the results and interpretations for our dataset without investing much of our efforts! And Smarten opts Classification tree algorithm as the best suited algorithm for our data selection with an accuracy as high as 99.84%. In a broader sense, Classification is the root algorithm technique but there are numerous algorithms which come under classification category. Smarten automatically works upon a list of widely used classification algorithms and designates the best choice model for our dataset.
Smarten opts Classification tree as the best suite algorithm for provided dataset
7. The purpose of Visualization is to obtain Insight!
Graphical representation of our data will help us look upon the trends and patterns in the data in an easy to understandable manner. In order to accomplish this, Smarten provides its users with smart visualizations to draw insights.
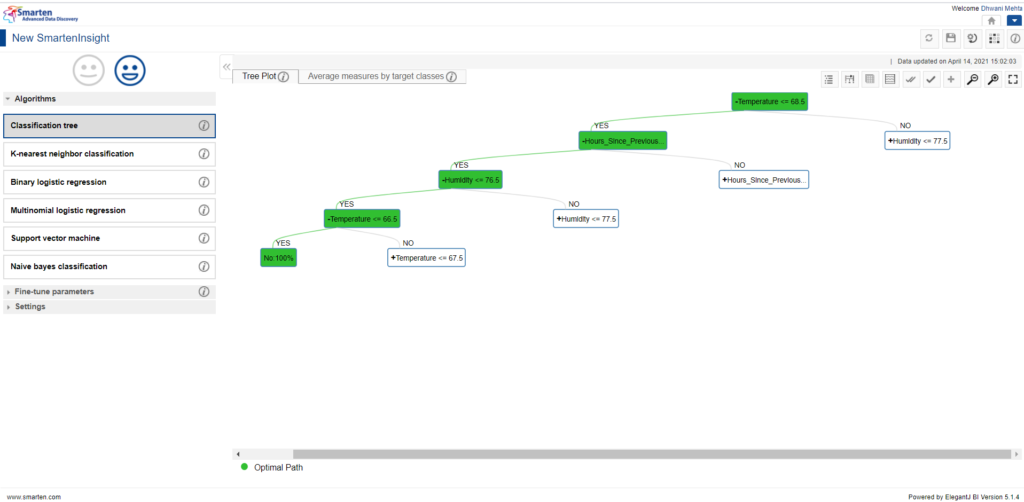
Tree plot visualization by Smarten Assisted Predictive Modelling
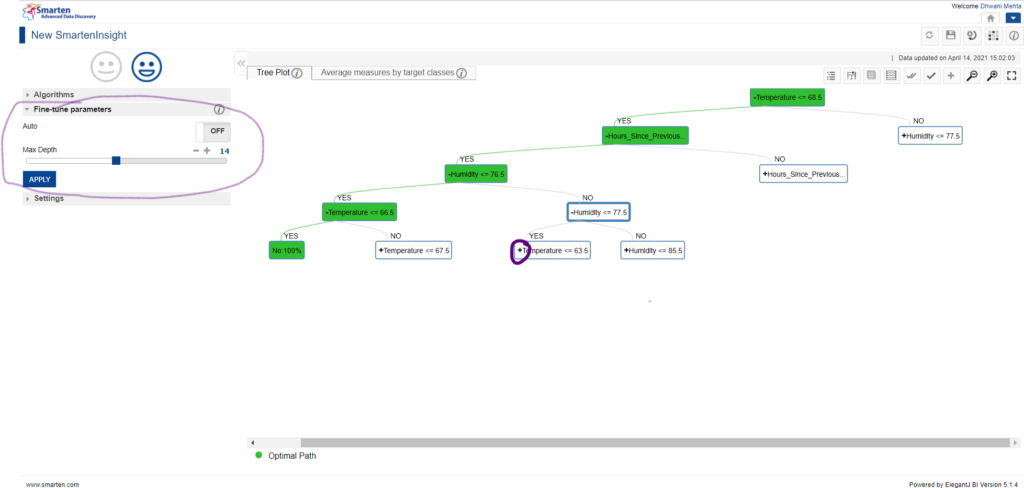
Classification tree plot visualization makes it easy to comprehend the parameters essential for obtaining a particular outcome. From the current visualization we can make out that temperature being the root node of the tree has utmost importance in impacting machine failure, followed by a bunch of further conditions as we traverse downwards. The depth of the tree indicates the number of conditions to be captured by the predictor variables in order to come to a conclusion. Deeper we allow the tree to grow, the more complex our model is. Smarten has a provision to allow its users to set the tree depth by fine tuning the depth parameter. On turning off the auto mode in the Fine-tune parameters option, we have flexibility in setting the max depth of the tree plot. Also, by default the tree doesn’t travel till its complete depth but only till the best optimal path depth. So, the users can explore the tree splits by clicking on the + icon provided at each internal node.
Fine Tuning of Classification Tree
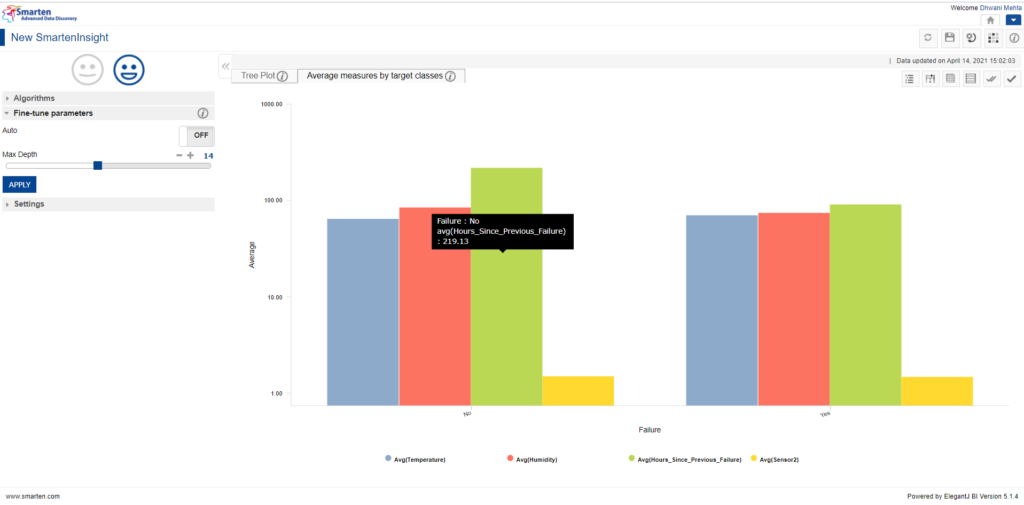
Apart from the tree plot, Smarten also provides us with average measures by target classes histogram for us to analyse how average measures are distributed across target variable classes. For the ongoing use case we perceive that in order to avoid machine failure, the average hours since the machine’s previous breakdown must be higher. Making us interpret that if the machine has not undergone failure in the immediate past, then it tends to survive longer. Note that this is not a generalized assumption we could make but is solely drawn from the data we provided!
Average measures by Target classes bar plot by Smarten Assisted Predictive Modelling
Smarten Assisted Predictive not only provides its users with easy to grasp visualizations but also provides us with a handy straightforward interpretation in layman language for better understanding upon the outcome so that its users can make business decisions effectively.
8. Having ample data, we starve for earnest insights!
Out of many features provided, Smarten Insight provides 4 key sections which will assist us in better interpretation of our data. Them being:
Interpretation
Model Summary
Single Apply / Mass Apply
Simulation
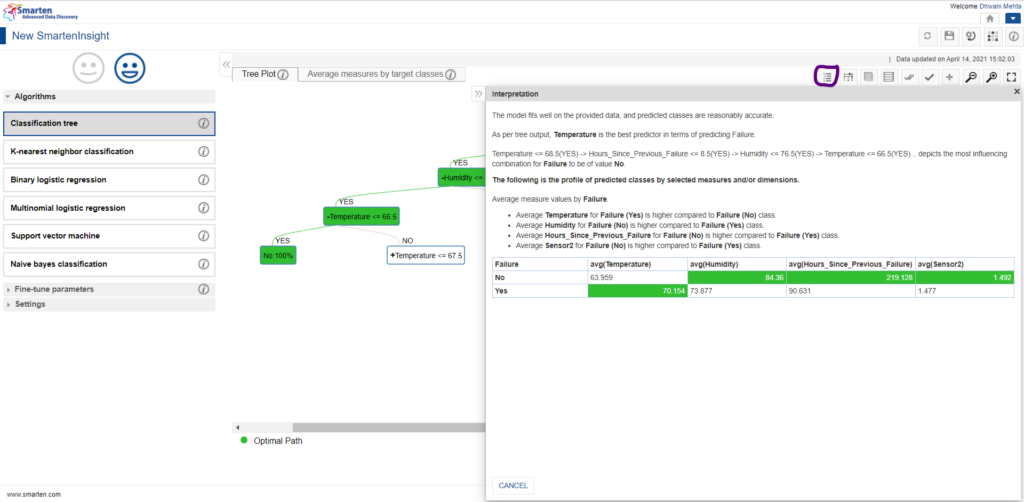
A. Interpretation:
The interpretation section provides the users an in-depth insight from the dataset in easy-to-understand language. It provides us with the entire profile of predicted classes based upon the selected predictors. Furthermore, it also provides us the effect of each and every attribute on the target (i.e., failure) both qualitatively (using tabular representations) and quantitatively (with average measure values). Having a look upon the interpretation section would help us acknowledge the key predictors as well as impact of underlying classes if any on the target and the average measure values for our targeted outcome. For our case study, we can conclude that temperature is the best factor influencing machine failure with it having a higher average value to be in a breakdown state.
Classification Tree Algorithm Interpretation for Machine Maintenance dataset
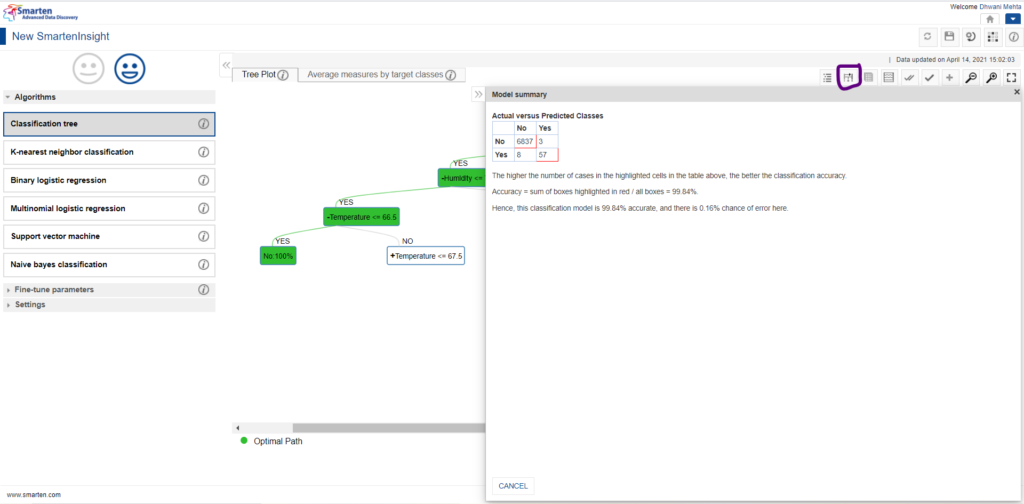
B. Model Summary :
The model summary section contains a more technical summary of the data. This is specially put to Smarten insight to provoke data Literacy. For instance, for carrying out classification of the model, data scientists make conclusions by making interpretations from the obtained confusion matrix, accuracy score and the error rate. Smarten provides us even this feature to validate the technical aspect with the generalized interpretations.
Model Summary for Classification Tree algorithm by Smarten Assisted Predictive Modelling
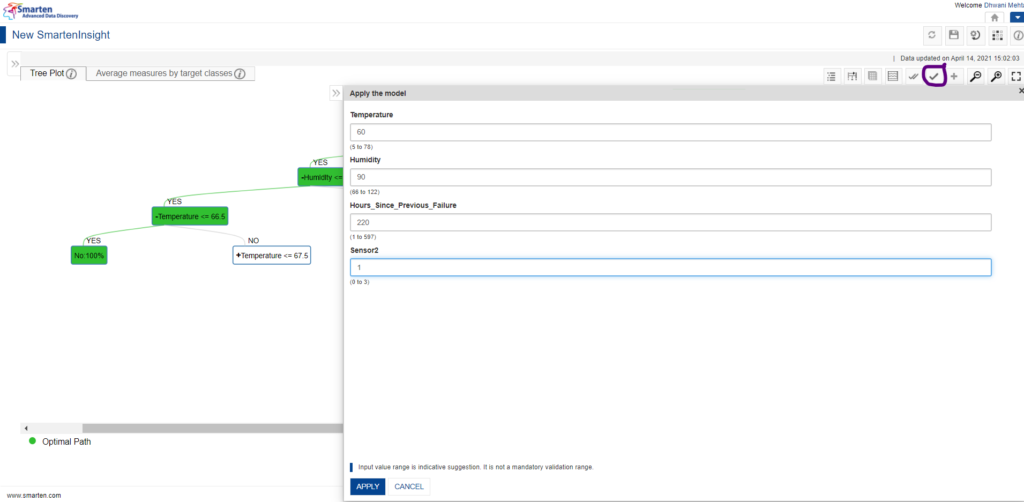
C. Apply the model:
Using the apply feature, the users can select/enter static values corresponding to every predictor variable and Apply the inputs in order to validate our interpretation and assist us in predicting the outcome (here whether the machine will fail) based upon any chosen feature set.
Apply the model option
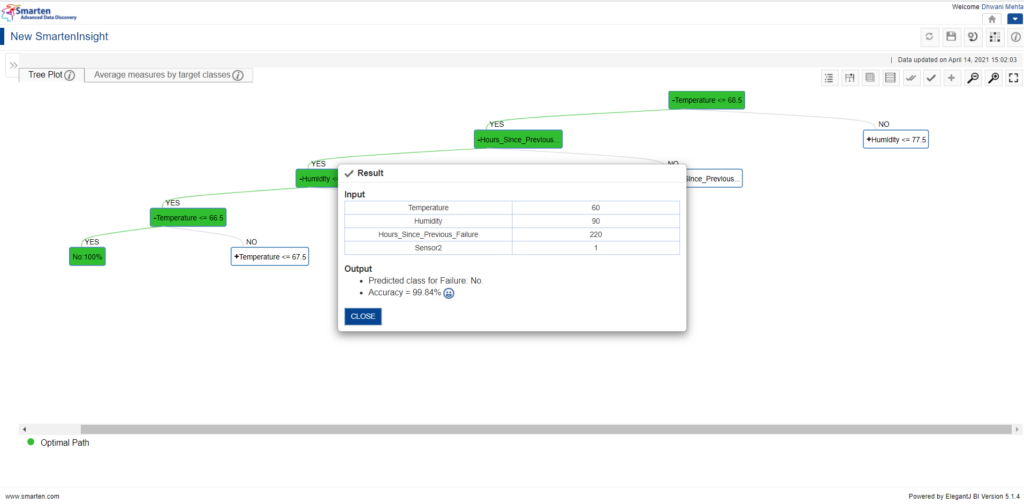
As the outcome of the apply feature, users can get to know the residing category (in this case machine failure yes or no) when the entered values are taken into consideration. Apart from this, we also come to the accuracy percentage (here 99.84%) with which we can assure our result. Also, we can sense that our interpretation quite resembles the outcome of the apply feature.
Predicted Result by applying the model
D. Simulation:
Simulation modelling feature serves at analysing the model prototype to predict its performance in real world scenarios. It helps the users understand under what conditions the outcome will withstand a particular outcome and make predictions in real time.
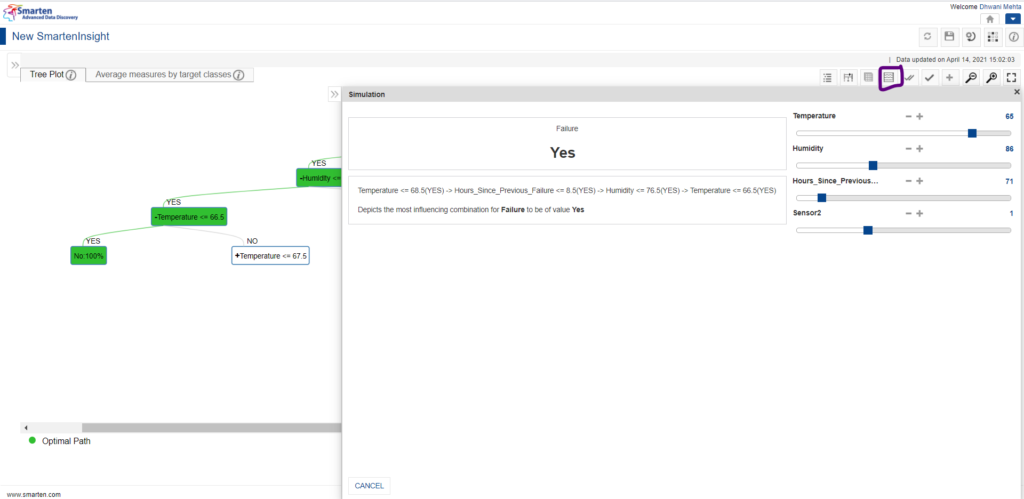
Say for instance, the user wants to make the settings of all the predictors in real time and make predictions, then the simulation feature can be used. We will find the icon for simulation on the top right corner of the screen. We could opt to scroll the feature values and predict whether the selected bunch of settings leads the machine towards failure condition or not with ease.
Simulation feature to predict outcome in real time
As it’s evident from the screen that there is a default setting made for each predictor unlike the Apply feature, and also the outcome when those default parameters are selected. One can change the parameters from the simulation and obtain the resulting category accordingly along with the most influencing combination leading to that particular category selection.
9. Every Choice we make has an end result!
Apart from the best fit algorithm automatically opted for by Smarten, the user also has a privilege to play around with other listed algorithms and review results produced by them for further analysis. Users can test the accuracy and other metrics of varied algorithms and make a comparative review upon all as well as make better explorations.
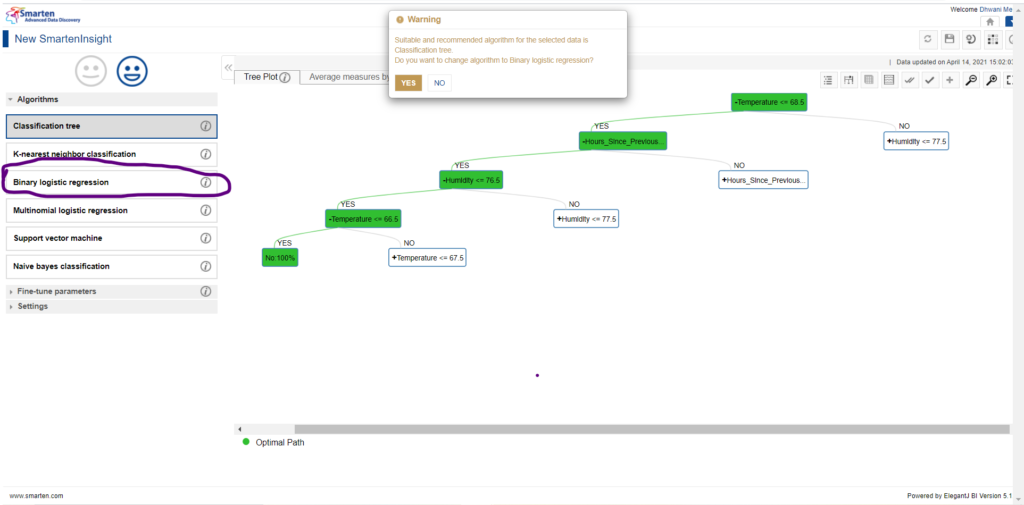
To make analysis and draw conclusions upon algorithms apart from the Classification Tree, just select the algorithm of interest on the left side menu list as follows (say for instance Binary Logistic Regression selection):
Note: Smarten makes sure that its users are well aware that the default selection is the best choice if the users want to save time on that grounds. But if a user wants to explore other algorithms, they can select the yes option and proceed.
Explore the machine maintenance outcomes based upon Binary Logistic Regression Algorithm
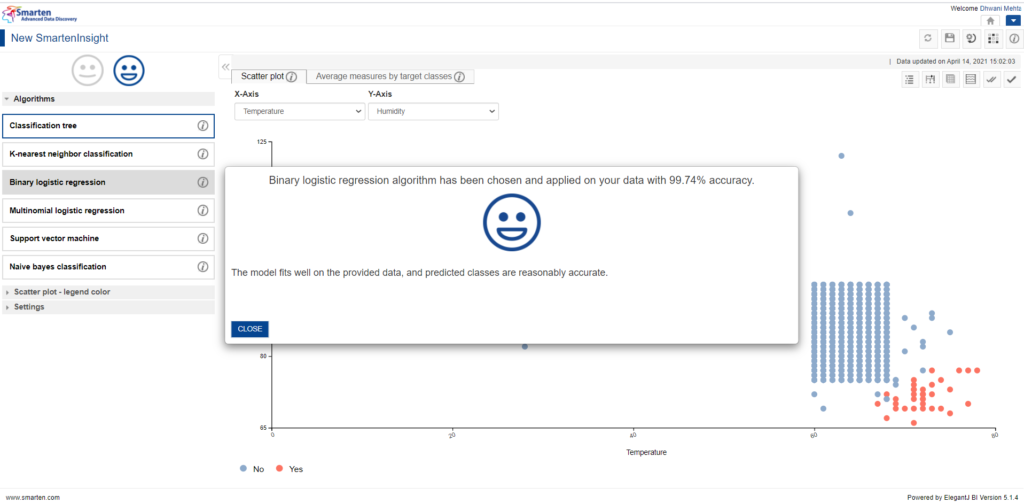
On selection, we will be driven to all the results, visualizations and interpretation of the use case as illustrated by the Binary Logistic Regression Algorithm.
Outcome from Binary Logistic Regression
It’s evident from the first glance that Binary Logistic Regression is not the best choice for our data owing to its lowered accuracy score compared to previously chosen Classification Tree algorithm by Smarten Assisted Predicted Modelling.
One can perform identical operations like lookup the interpretation, model summary etc. in all the algorithms and take the beneficial insights. After all every algorithm can provide us with inquisitive insights!
Also, it’s not always a scenario wherein any algorithm can be applicable to any dataset. There are some regulations for every machine learning algorithm which the data must satisfy in order to perform analysis with. Smarten has provided apt pop-ups if our data is not suited for the algorithm selection.
10. Ready, Set, Go!
Now that we have a made a step-by-step approach in understanding the flow of making analysis for the Machine Maintenance use-case using Smarten Assisted Predictive Modelling with a generic sample data, we are all set to make similar process in tackling any other dataset with provided predictors and targets as per business requirements and create corresponding model to analyse the outcomes as well as apply this model to provided machine data to understand whether the machine will fail based upon the sensor recordings and affecting environmental factors!
Note: This article is based on Smarten Version 5.1.1. This may or may not be relevant to the Smarten version you may
We use cookies to personalise content and ads, to provide social media features and to analyse our traffic. We also disclose information about your use of our site with our social media, advertising and analytics partners.