


1. About the Use Case :
Customer churn alternatively referred to as customer attrition indicates that the customer (or user or subscriber etc.) cease to do business with the company or service provider. Higher value of churn suggests that the customer is no longer willing to purchase goods or services from your business. The ability to predict that a particular customer is at a high risk of churning, while there is still time to do something about it, represents a huge additional potential revenue source for any business. Furthermore, it is always more difficult and expensive to acquire a new customer than it is to retain a current paying customer. Being a critical metric in hindering business growth, companies must be aware about its customer churn rate in order to monitor revenue success as well as determine strategies for customer retention.
2. Data has a better idea!
Now that we have a good understanding of what customer churn use case is, the next obvious step is to analyse it. Any kind of analysis initiates by looking upon the data. Keeping a note that we already have a predefined dataset uploaded to Smarten, let’s get started slowly but surely into how to open a loaded dataset in Smarten and make analysis.
Steps to Open a loaded dataset in Smarten :
- Go to Open -> Data in top right dropdown in Smarten
- Search for the dataset to analyse
- Examine the dataset
On opening the dataset, you will be able to view the attributes(columns) affecting the use case and also be able to draw some superficial insights by pondering upon the dataset. Your dataset will look as follows:
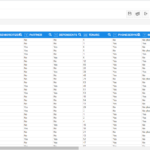
Perform Elementary Data Analysis from Dataset:
From the dataset, we can see that our dataset contains many attributes/features upon which our target variable (i.e. churn) depends. Churn is evidently splitted into two categories (i.e. yes and no) based upon the depending features. The following are the features which our dataset contains:
- CustomerID
- Partner
- PhoneService
- OnlineSecurity
- TechSupport
- Contract
- MonthlytCharges
- SeniorCitizen
- Tenure
- InternetService
- DeviceProtection
- StreamingMovies
- PaymentMethod
- Gender
- Dependents
- MultipleLines
- OnlineBackup
- StreamingTV
- PaperlessBilling
- TotalCharges
In layman terms, we can depict that the customer churn rate has high dependency upon the Monthly Charges, Contract, Tenure, Total Charges and may be on dependents. But this calculation varies from company to company and the type of data we have.
For validating our assumptions as well as to obtain extensive insights from the data, Smarten provides a straightforward approach to understand the data better and to get the required outcome for the use case.
Now it’s time to gear up with some amazing data analytics using Smarten !!
3. The goal is to turn Data into Information and Information into Insight !
Smarten provides us a feature of Smarten Assisted Predictive Modelling which reduces the time and skills required to produce accurate, clear results, quickly using machine learning. With Smarten Insights, the user will simply have to select the dataset to be analyzed and the broad category of the algorithm to be applied. That’s it!. The system will interpret the dataset, select important columns of data, analyze its type and variety and other parameters and then use intelligent machine learning to automatically apply the best algorithm in the selected algorithm technique in order to provide data insights.
Let’s gradually familiarize with Smarten Insights!
- Create a fresh New Smarten Insight :
GotoNew ->SmartenInsight Menu in the dropdown provided in the top right corner of the Smarten Dashboard.
2. What do you want to do? Choose Algorithm Technique Accordingly:
The following window opens on selecting Smarten Insight:
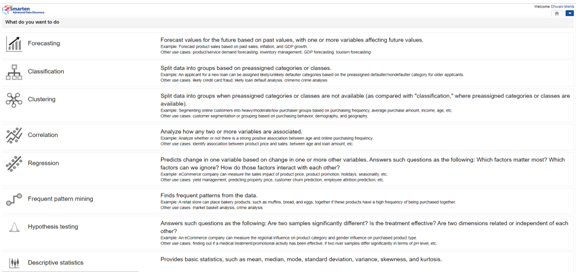
Smarten has a provision wherein users can select the algorithm technique best sufficing their use case and provide quality results for the chosen technique. In order to select the best category of algorithm, users need to have some basic data literacy.
We need to choose the best algorithm technique from the following list:
- Forecasting
- Classification
- Clustering
- Correlation
- Regression
- Hypothesis Testing
- Frequent Pattern Mining
- Descriptive Statistics
Let’s put our thinking caps on and try to recognize the best suit algorithm technique for Customer Churn dataset !
The high level goal is pretty clear that we are keen to predict whether the given customer will churn provided other parameters. So we are basically interested in splitting (or categorizing) our outcome based upon whether the customer will churn (yes) or not (no). This suggests that our problem can be prototyped as a classification task because our outcome domain is finite (i.e. outcome has only two values, churn and non-churn).
Acknowledging this study, we can carry forward with our process of getting insights using Smarten by selecting the Classification model from the list of other algorithms. Smarten also has a provision to provide description against each algorithm technique along with a basic example to enhance data literacy and assist us in algorithm selection.
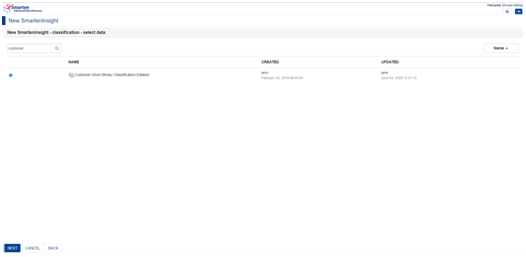
3. Select the data for Performing Classification upon:
- Search for the dataset (In our case it’s named Customer Churn-Binary Classification-Dataset) from the search bar.
- Select the radio button against the dataset of interest.
- Click on the next button at the bottom to advance the procedure.
4. Wait till Smarten is predicting the targets (outcome variable) and predictors (dependent variable) for us:
5. Select the target and predictors based upon your choice:
After Smarten identifies the target and predictor columns as showcased below, we can change the settings as per our requirements.
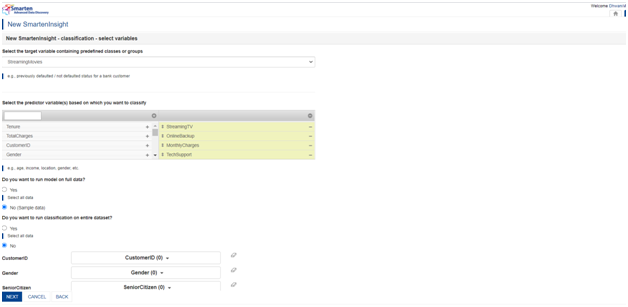
5.1Target selection:
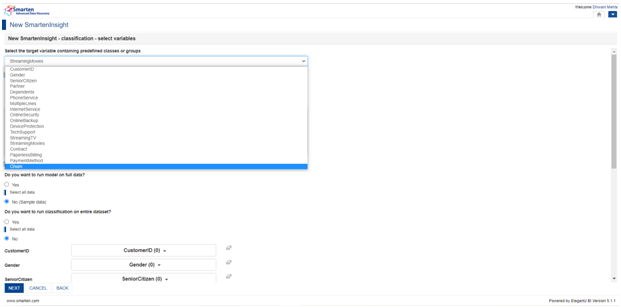
We would want Churn to be our target variable so we can select that from the dropdown indicating ‘Select the target variable containing predefined classes or groups’.
5.2 Identify recommended predictors for selected Target:
Smarten has a feature wherein it selects the significant predictors for the chosen target using machine learning techniques. If you want to select the significant predictors by Smarten mechanism, there is a pop up recommending us to use them as follows:
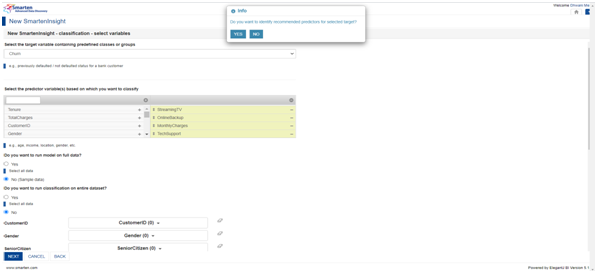
After selecting Yes option we have to wait till Smarten automatically obtains the significant predictors.
5.3 Perform changes in Predictors (Optional):
Now that Smarten has well equipped us well with the predictors, we still have a choice to add or remove the predictor selections based upon our interest.
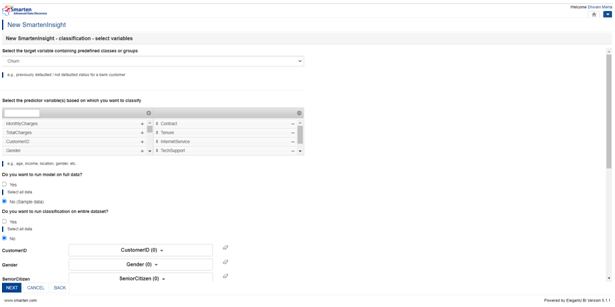
The right-side table of Predictors represents those which significantly affect the target (here Churn) and the left side contains the remaining predictors. The predictors on the right side table will be feeded to the machine learning model to generate outcomes. So we can make alteration in the right side list of predictors using the + and – symbols before processing further.
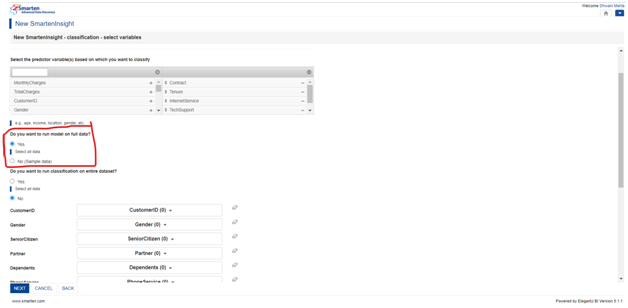
5.4 Run model on full or sample data option:
Sometimes, perhaps in most cases, we have to deal with huge data. Our machine learning model may take more time to run and provide us with the required outcome. In such a scenario Smarten provides us with an option of using sampled data wherein it smartly makes a sample of data resembling the full data which may give us the same result set as we would have obtained in the full data.
But in our current scenario, we can use the full data to feed to the model by selecting the radio button as follows:
5.5 Want to run classification on entire dataset option:
Often users want to make analysis upon some filtered data. Say for instance what if we were to find the customer churn rate only for females? In such a scenario, we need to select our gender to be female, keeping all the predictors as they are. For such filtering of data Smarten provides us with an option to run classification on entire dataset or filtered dataset as follows:
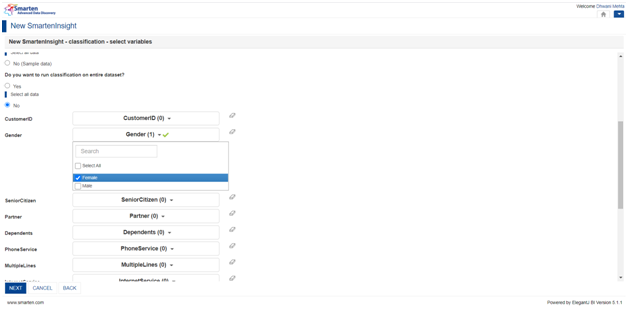
If we have no such filtering condition in mind, we can carry further with yes option.
After well performing the above effortless process, finally click on the next button which will let Smarten designate the best fit classification algorithm using machine learning tactics for our dataset.
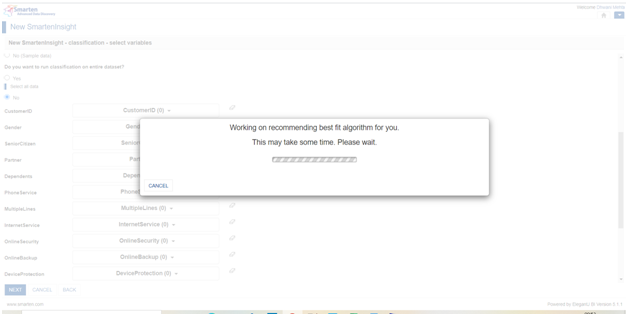
4. So that was the recipe, Now let’s taste it !
On clicking the next button, Smarten leads us to the results and interpretations for our dataset without investing much of our efforts!
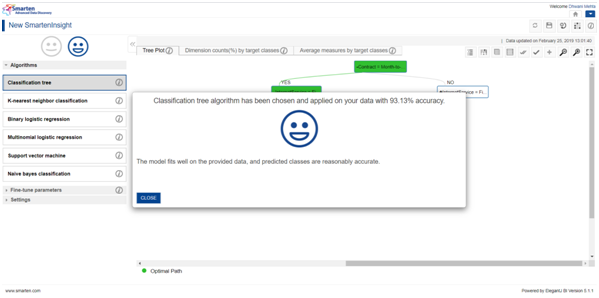
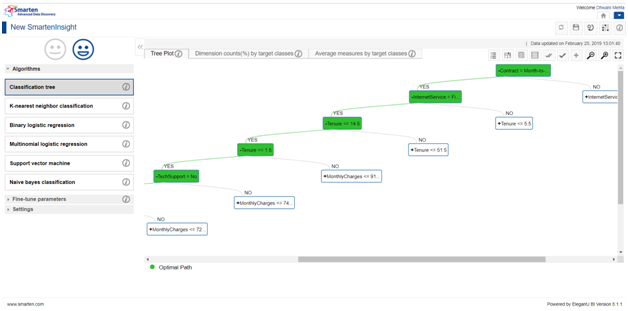
In a broader sense, Classification is the root algorithm technique but there are numerous algorithms which come under classification category. Smarten automatically works upon a list of widely used classification algorithms and designates the best choice model for our dataset. In the above case, we can see that Smarten has suggested to us the Classification Tree to be the best choice algorithm for our data selection.
Smarten not only provides its users with easy to grasp visualizations but also provides us with a handy straightforward interpretation in layman language for better understanding upon the outcome so that its users can make business decisions effectively.
5. Every Choice we make, has an end result!
Apart from the best fit algorithm automatically opted for by Smarten, the user also has a privilege to play around with other listed algorithms and review results produced by them for further analysis. Users can test the accuracy and other metrics of varied algorithms and make a comparative review upon all as well as make better explorations.
To make analysis and draw conclusions upon algorithms apart from the best fit one, just select the algorithm of interest on the left side menu list as follows (say for instance Support Vector Machine selection):
Note: Smarten makes sure that it’s users are well aware that the default selection is the best choice if the users want to save time upon that grounds. But if a user wants to explore other algorithms, they can select the yes option and proceed.
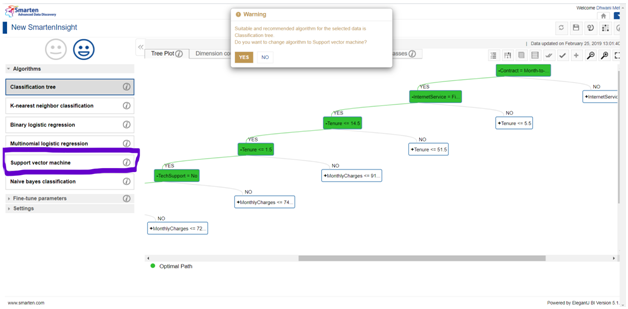
On selection, we will be driven to all the results, visualizations and interpretation of the use case as illustrated by the Support Vector Machine Algorithm.
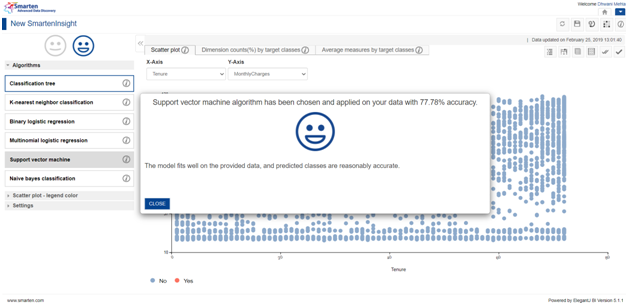
It’s evident from the first gaze that SVM is not the best choice for our data owing to its lowered accuracy score compared to previously chosen Classification Tree algorithm by Smarten.
One can perform almost identical operations like lookup the interpretation, model summary etc. in all the algorithms and take the beneficial insights.
Also, it’s not always a scenario wherein any algorithm can be applicable to any dataset. There are some regulations for every machine learning algorithm which the data must satisfy in order to perform analysis with. Smarten has provided apt pop-ups if our data is not sustainable for the algorithm selection. For illustration, K-nearest neighbor algorithm is only applicable for numeric variables and with outcome category to be more than two (but we only have two categories in this case i.e. churn yes and churn no):
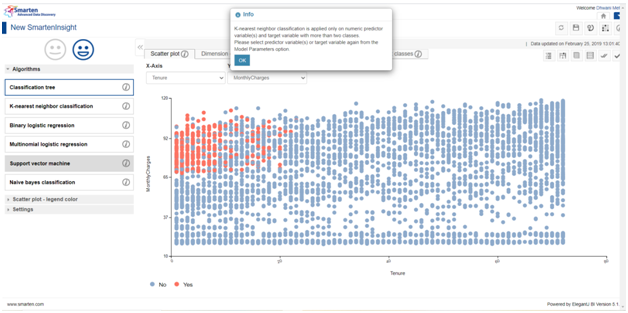
6. Simpler the Insight, more profound the Conclusion !
Out of many features provided, Smarten insight has 3 key sections which will assist us in better interpretation of our data. Them being :
A. Interpretation
B. Model Summary
C. Apply
D. Simulation
A. Interpretation :
The interpretation section provides the users an in-depth insight from the dataset in easy to understand language.
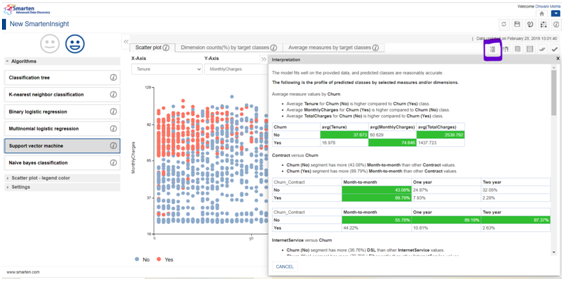
For current scenario, the interpretation provides us with the entire profile of predicted classes based upon the selected predictors. Furthermore, it provides us the effect of each and every attribute on the target (i.e. churn) both qualitatively (using tabular representations) and quantitatively (with average measure values). Having a look upon the interpretation section would help us acknowledge the key predictors as well as impact of underlying classes if any of the predictors on the target and the average measure values for our targeted outcome.
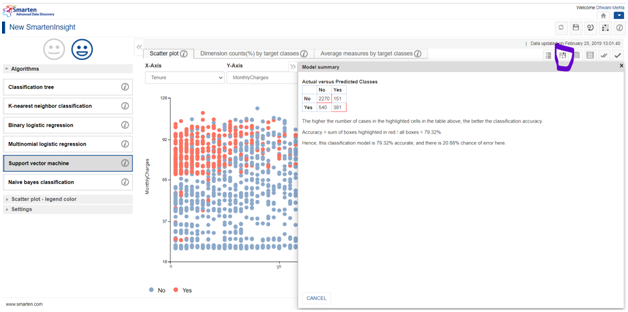
B. Model Summary :
The model summary section contains a more technical summary of the data. This is specially put to Smarten insight to provoke data Literacy. For instance, for carrying out classification of the model, data scientists make conclusions by making interpretations from the obtained confusion matrix, accuracy score and the error rate. Smarten provides us even this feature to validate the technical aspect with the generalized interpretations.
C. Apply the model :
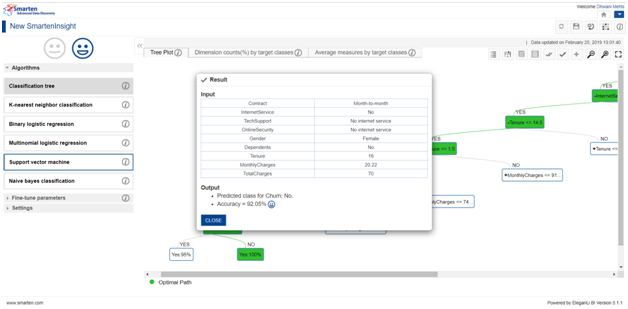
Using apply feature, the users can select/enter static values of each variable on pressing the Apply button Smarten let us know the outcome (here churn yes or no). This is specially used when we have predefined values of all the other variables and keen to know the target class accordingly.
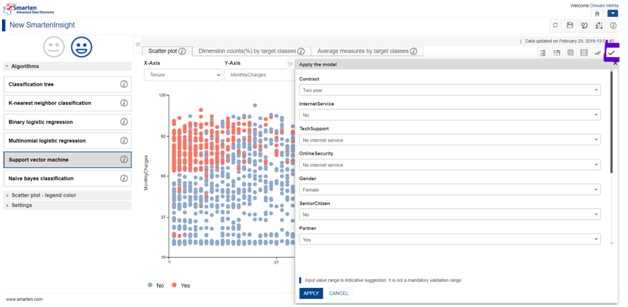
As the outcome of the apply feature, users can get to know the residing category (in this case churn yea or churn no) when the entered values are taken into consideration. Apart from this, we also come to the accuracy percentage with which we can assure our result.
D. Simulation :
Simulation modelling feature assists in analyzing the model prototype to predict its performance in real world scenarios. It helps the users understand under what conditions the outcome will withstand a particular outcome and make predictions in real time.
Say for instance, the user wants to make the settings of all the predictors in real time and make predictions, then the simulation feature can be used. We will find the icon for simulation on top right corner of the screen as follows:
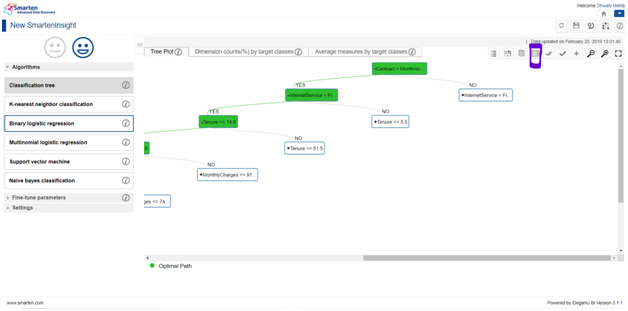
On clicking the simulation button, we will be landed to a screen for making our simulations as follows:
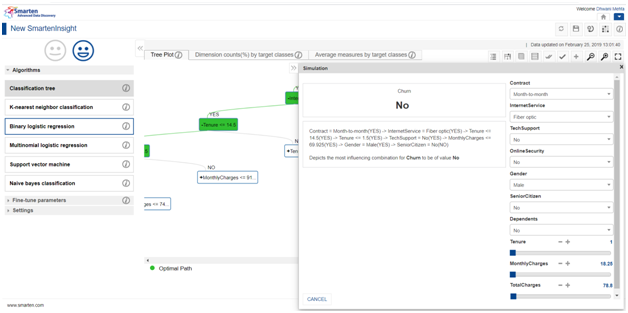
As it’s evident from the screen that there is a default setting made for each predictor unlike the Apply feature, and also the outcome when those default parameters are selected. One can change the parameters from the simulation and obtain the resulting category accordingly along with the most influencing combination leading to that particular category selection.
7. Ready, Set, Go!
Now that we have a made a step-by-step approach in understanding the flow of making analysis of the Customer Churn use-case using Smarten using a sample data and model, we are all set to make similar process in tackling any other sample data with provided predictors and targets as per business requirements and create corresponding model to analyze the outcomes as well as apply this model to provided customers data to understand who is at risk to move away from you!
Note: This article is based on Smarten Version 5.0. This may or may not be relevant to the Smarten version you may be using.
Original Post : Customer Churn Model Using Smarten Assisted Predictive Modelling!
 Augmented Analytics Support, Business Intelligence Support, Smarten Support, Smarten Training
Augmented Analytics Support, Business Intelligence Support, Smarten Support, Smarten Training







